Linux 系统管理与常用指令
Linux
linux的历史
unix
1970,贝尔实验室的工程师因开发的游戏无法继续在贝尔实验室的系统上继续使用,开发了unix来继续运行游戏
特点:
- 多任务、多用户
- 多用户:多个用户可以在同一时间使用同一个linux系统
- 多任务:Linux中可以同时运行多个程序,执行多个任务
- 有网络
- 并行处理,稳定性好
- C编写,可移植性强
- 多任务、多用户
linux
1987,荷兰教授因unix系统版权被收回,讲操作系统原理课不方便。开发了minix。芬兰的linux在minix上增加功能,并与1991年将其上传到互联网成为linux(跟准确的说linux发布的是linux kernel)
特点:
- 承袭unix的特点(多任务、多用户、网络、并行处理、稳定性和移植性好)
- 常用来搭建网络服务器,LAMP(linux + Apache + MySql + PHP) 和 LNMP (linux + Nginx+ MySql + PHP)就是使用极为普遍的web服务平台。
- 广泛应用于嵌入式系统。手机、机顶盒、路由器等。
linux的内核——kernel
kernel:
完成操作系统最基本功能的程序。
运行在硬件之上,是所有应用程序运行的基础。是计算机硬件和用户之间的桥梁。通过它,我们才能让CPU处理各种数据,在硬盘中读写各种数据,与网络上的计算机进行通信
最基本的功能:
管理形形色色的硬件设备
提供用户操作界面
提供应用程序的运行环境
linux = kernel + 应用程序(linux系统桌面也是应用程序)
linux的发型版本
linux kernel 符号GUN协议,任何人可以免费使用,并修改。
RedHat Linux
RHEL(企业付费版,提供技术支持和定制第三方软件)和 Fedora(免费版)
CentOS
在RHEL开放出的源代码基础上二次编译而成的linux系统,命令操作和服务配置方法与RHEL相同,去掉了RedHat的收费套件
Debian
以稳定著称的免费linux系统,有很多服务器采用Debian作为操作系统。
基于Debian二次开发出的有:Ubuntu 和 Kali Linux
SUSE
在欧洲流行的linux发行版,不适合初级用户。
有 企业版SUSE 和 openSUSE
VMware
虚拟机的架构
我们平时使用的虚拟机,是寄居架构(虚拟化软件在操作系统上安装)。企业使用的是裸金属架构(原生架构:在硬件上直接安装虚拟化软件),两者的性能有天壤之别。
虚拟机的网络
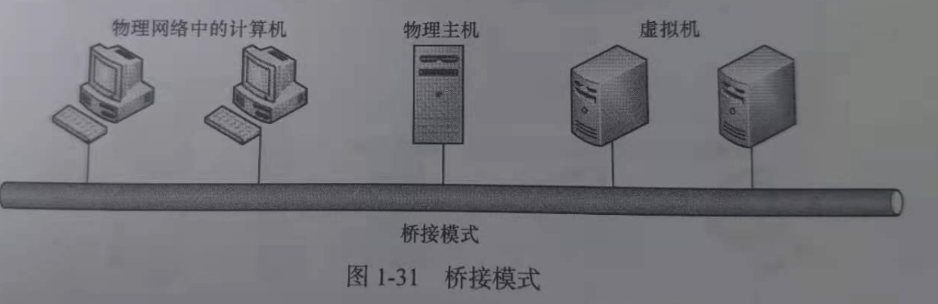
桥接模式(bridged)
虚拟机类似一台物理机,可以访问外网,外网的计算机也可以访问该虚拟机。
将虚拟机的IP设置为与物理机的IP同一个网段,则虚拟机可以与该局域网中的物理机和其他主机通信。
桥接模式对应的虚拟网络名称:VMnet0
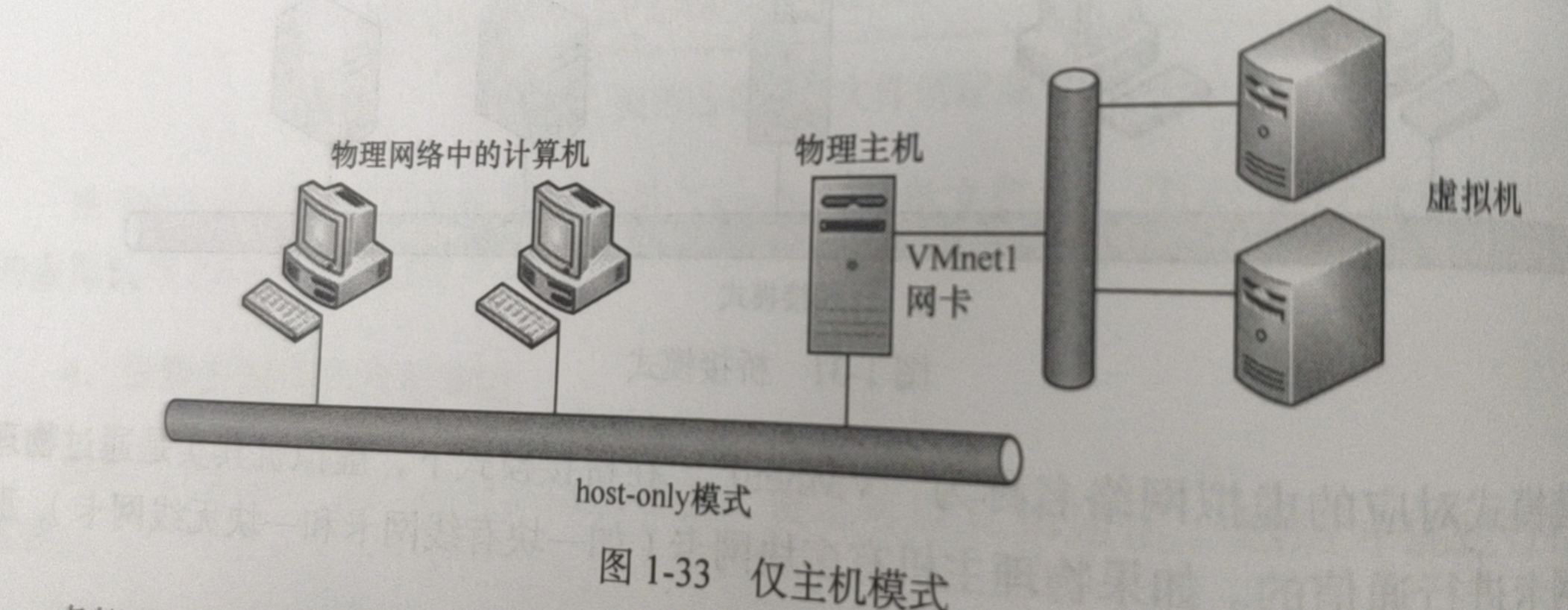
仅主机模式(host-only)
虚拟机在一个独立的虚拟网络中,与物理网络之间是隔离的。所有仅主机模式的虚拟机之间以及虚拟机与物理机之间可以互相通信,但是它们与外部网络的主机无法通信。
仅主机模式对应的虚拟网络名称:VMnet1,物理主机要与仅主机模式下的虚拟机通信,需要保证VMnet1网卡的IP与虚拟机IP在同一网段。
NAT模式(网络地址转换)
NAT模式对应的虚拟网络名称:VMnet8。
与仅主机模式类似,虚拟机也是处于与物理网络隔离的独立的网络中。但是此时,物理主机作为一个支持NAT功能的代理服务器,虚拟机可以作为客户端,通过物理主机的IP地址访问外部网络的计算机,但是由于NAT技术的特点,外部网络中的计算机无法主动与NAT模式下的虚拟机进行通信,只有虚拟机到外部网络计算机的单向通信。
Shell
shell也属于应用程序。
shell 就是 Command Line Interface。将用户的命令解释为系统内核可以理解的语言,内核执行以后,将结果以用户可以理解的方式显示出来。

shell的实现有多种:sh、Csh、Zsh和Bash。CentOS默认使用Bash,这也是目前应用最为广泛的一种shell。
命令提示符
[lifeisbinary@centos-linux ~]$ 【终端当前用户@主机名 当前所在目录】 $ ——普通用户; #——管理员
用户切换命令: su - root 实现不同权限的操作
用户在本地所打开的终端称为虚拟终端TTY,用户在远程所打开的终端称为伪终端PTS。
Shell的格式
命令名 【选项】 【参数】
命令名:必不可少
选项:调节命令的具体功能,用“-”开头。选项即可以有一个,也可以有多个。 如 ls -l -a 与 ls -la
部分选项以“–”开头, 如 ls --help
shell中,一行可以输入多条命令,命令之间用分号隔开。如果在一行命令后加上 “\”,可以进行换行
命令区分大小写
关机和重启命令
单用户时使用,只保存当前用户的更改,其他用户的更改会丢失。
poweroff
reboot
多用户时使用,因为可以发送提示信息所以更加安全
shutdown -h now //立即关闭系统
shutdown -r now
shutdown -h +15 //15min后重启
shutdown -h +15 ‘the system will be rebooted!!' // 15min以后系统重启,并发送设定的信息给登陆到本机的各用户
Ifconfig 网卡名 IP地址 //配置网卡的IP地址
tip:如果两台主机之间网络通信出现问题,可以使用ping从一台主机去ping另一台,如果ping不通,可能是因为另一台主机开启了防火墙。可以通过另一台主机去pint当前这一台,来排出这种可能性。
远程登录到linux,以前采用telnet,但该方式的数据以明文传输不安全。现在主要采用SSH,默认端口号TCP22
远程登录使用的工具: XShell、SecureCRT、PuTTY
文件管理和目录管理
Linux中一切皆文件:数据、其他资源(包括硬件设备)以文件的形式组织起来。例如,硬盘以及硬盘中的每个分区在Linux中都被视为一个文件。用户可以像使用普通文件那样对设备进行操作。
Linux使用纯文本保存配置信息:无论是Linux系统本身还是应用程序,他们的配置信息往往都保存在一个纯文本的配置文件中。如果需要改动系统或者应用程序中的某项功能,那么只需要编辑相应的配置文件。
目录管理
Linux系统使用“/”进行分隔路径中目录的分隔(window使用“\”)
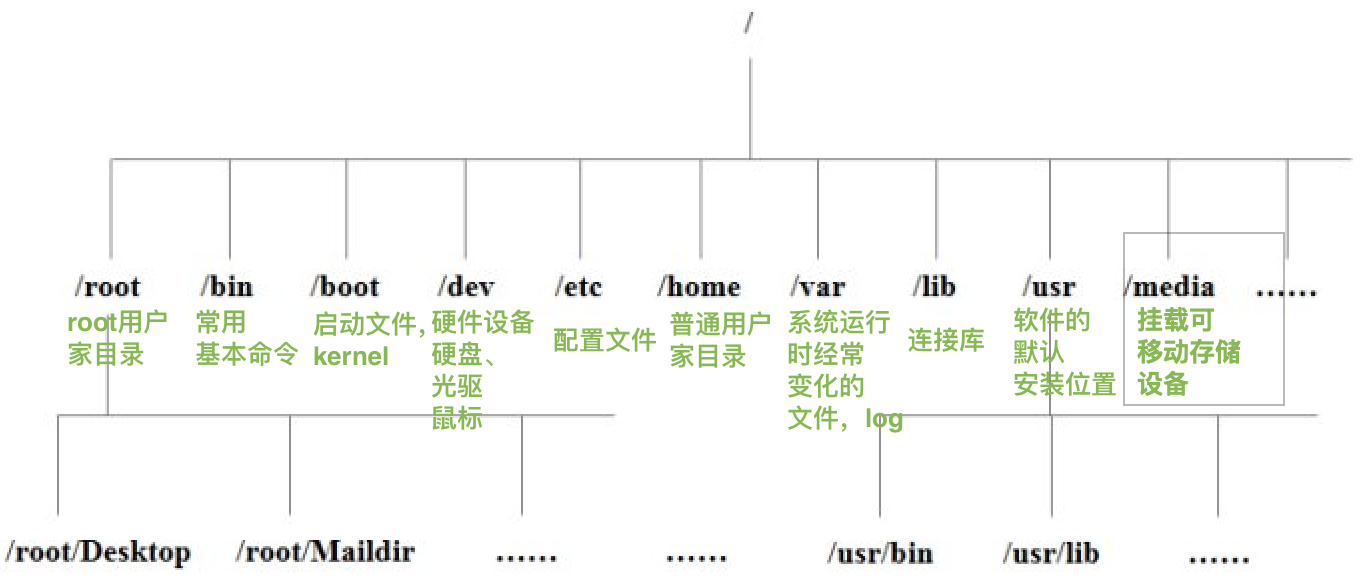
/mnt 一般是空的,用来临时挂载存储设备
/proc 存储系统内核和进程的相关信息
/run 存放进程产生的临时文件,系统重启后会消失
/lost+found 存放系统意外崩溃或者关机时产生的文件碎片
pwd //打印当前目录
cd - //在最近工作过的两个目录之间切换
ls
ls or ls 文件或目录名 //目录内容列表展示,结果:蓝色——目录,灰色——通文件,绿色——可执行文件,红色——压缩文件,浅蓝色——链接文件
ls -a //显示所有文件,包含隐藏文件
ls -l //显示美国文件的详细信息
drwxr-xr-x:
- 第一个字符:d——文件夹,- ——普通文件,l——链接文件,【硬件设备 c——字符设备,b——块设备】
- 其余六个代表文件的权限
设备文件分为块设备和字符设备,块设备支持随机访问,而字符设备则只能线性访问。键盘是字符设备,硬盘是块设备。
2: 被硬链接的次数,文件默认为1,目录默认为2。(linux中的链接文件类似于window中的快捷方式)
lifeisbinary: 文件的所有者
lifeisbinary: 文件所属的组
4096:文件的大小,对于目录只显示目录本身的大小,不显示目录所包含内容的大小
6月 12 2020:文件被创建或者最近一次修改的时间
Desktop:文件名
ls -ld 目录 显示目录本身的信息而不是,目录内部的信息
ls -lh 文件的容量用 KB、 MB、GB等单位显示
touch
touch newfile //创建新文件
mkdir 和 rmdir
mkdir newDirectory //创建文件夹
mkdir a b c //创建多个文件夹
mkdir -p ~/newfilm/HKfilm //创建嵌套的多级目录结构
cp、mv和rm
cp 复制文件
cp /etc/network.conf /home/ //复制到指定的文件夹
cp /etc/network.conf /home/newnetwork.conf //复制到指定文件夹并重新命名
cp 复制文件夹
cp -r /home/film/ /home/newfile/ // -r 递归复制所有文件和目录
cp -p // -p 在复制中保证文件和目录的属性(所有者和所属组)不发生变化
mv 移动文件或者重新命名
mv /home/film/china.txt /home/film/china/ //移动文件
mv /home/film/china.txt /home/film/currentFilm.txt //文件重新命名
mv 在移动文件夹时不需要添加像cp命令一样的-r选项,就可以直接移动文件夹
rm 文件删除、目录删除
rm newfile.txt //文件删除
rm -f newfile.txt //文件删除,跳过询问确认
rm -rf film/ //文件夹删除
在生产环境中,为了安全起见一般不是使用 rm -rf。如果要删除某文件或者目录,使用mv将其移动到一个专门设置的回收目录,过一段时间之后,确认不再需要这些文件或目录,再用rm命令将其彻底删除。
通配符
通过特殊的符号,对多个文件进行批量的选择,并用shell命令处理
*:匹配任意数量的任意字符
eg:ls -d /etc/pa* //列出etc目录下所有以pa开头的目录或者文件
rm -f /tmp/*.txt //删除/tmp目录下的所有txt文件
?:配置任意单个字符
eg:ls -lh /dev/sd? //列出/dev目录下所有以sd开头只有三个字符的文件信息
[]:配置指定范围的任意单个字符
eg:ls /dev/[df]?? // 列出/dev目录下所有以“d“和”f“开头并且文件名为三的文件
ls /dev/[a-c]* // 列出/dev目录下所有一个“a”、“b”和“c“开头的文件
ls /dev/???[0-9]* // 列出/dev目录下文件名的第四个字符是数字的文件
在[]中还可以使用!指定不再选择范围的字符
eg:ls /dev/[!fhi]* // 列出/dev目录下不以“f”、“h”和”i“开头的文件
扩展符
{}中可以包含一个以逗号分隔的列表,并将其自动展开为多个路径或文件名。
eg:mkdir /tmp/{a,b,c} //一次性创建/tmp/a、/tmp/b和/tmp/c三个目录
touch /tmp/test{1..10}.txt //在/tmp目录下一次性创建 test1.txt , … , test10.txt共10个文件
文件内容操作
cat——小文件查看
cat -n /etc/passwd //显示文本文件的内容,-n显示行号
cat会一次显示完所有的文件内容,并且只保留最后一页在屏幕上,不方便查看长文件。
less and more ——长文件查看
less -N /etc/passwd
more -N /etc/passwd
less,more 命令适合与长文件阅读
less具有翻页功能,到文件末尾需要手动退出——适合查看长文件
more只能向后翻页,并且到文件末尾自动退出——与其他命令结合使用
tail and head —— 文件部分查看
head and tail 默认只显示10行内容
head -2 /etc/passwd //查看文件的前两行内容
tail -2 /etc/passwd //查看文件的后两行内容
tail -f /var/log/messages //查看系统公共日志文件messages的最后10行内容,并在末尾跟踪显示该文件中实时更新的内容。
tail命令更多的被用于查看系统日志文件,以便观察相关的网络访问、服务调试信息。配合-f选项可以用于跟踪日志文件末尾的内容变化,实时显示更新的日志内容。
wc——文件内容统计
wc /etc/passwd //输出passwd文件的 行数、单词数、字节数
echo——输出指定的内容
输出字符串
echo "Hello world!"
输出变量
echo $SHELL
echo $day //自定义变量 day = ""Sunday前提下
echo命令常与>和>>重定向符结合,将内容保存或者追加到文件中
echo 'hello world' > test.txt //覆盖
echo 'good bye world' >> test.txt //追加
echo的输出会默认换行,添加 -n 后可以不产生换行效果
文件内容查找——grep
grep: 在文件中查找并显示指定字符串的所有行。
grep [选项] 查找条件 目标文件
grep "root" /etc/passwd //在/etc/passwd文件中查找包含“root”字符串的行
grep命令在设置查找条件时,不支持“ * ”和“ ?”等通配符,而是使用正则表达式设置条件。
grep "^root" /etc/passwd //查找以root开头的行
grep "^$" /etc/passwd //查找空白行
-n:输出行的行号
-v:找出不符合查找条件的行
-i:查找条件不区分大小写
-w:精确匹配单词(含有这个单词的其他单词不会被显示)
文件内容对比——diff
diff命令用于比较多个文本文件之间的差异,这在系统安全防范中非常重要。例如,在黑客入侵系统后,往往会修改一些系统配置文件,从而留下“后门”。作为运维人员,最好事先将一些重要文件备份,然后定期执行diff命令进行对比,从而发现文件是否被改动过。
在进行如下操作后
1 | [lifeisbinary@centos-linux ~]$ cp .bashrc .bashrc.bak #文件备份 |
进行比较
12d11:
文件1(.bashrc)的第12行在文件2(.bashrc.bak)中被删除了(d代表删除)
< cd /tmp
以<开始的行属于文件1(.bashrc),以>开始的行属于文件2(.bashrc.bak)
cd /tmp 为被删除的行

时间和日期相关命令
Date——打印、修改日期
date //按照系统默认的格式显示日期和时间
date +%F //只显示日期
date +%T //只显示时间
date 050517002021 //将当前日期修改为2021年5月5日17:00
hwclock——显示或修改硬件时钟
在linux系统中存在两套时钟系统:date命令查看的系统时间 和 记录计算机BIOS中的硬件时钟。两套时钟所显示的时间可能会不一致。
由于没次重启系统的时候,系统都会重新从BIOS中将时间读取出来,所以要修改日期和时间,单单执行date命令还不够,还必须再用hwclock命令来更新硬件时钟。
如果发现两者不一致:
1 | hwclock -w #将系统时钟写入硬件时钟 |
文件元数据查看——stat
linux系统中文件包含两部分:
- 文件内容(cat、more、less等查看的内容)
- 文件元数据,用于描述文件本身的属性,文件大小、存储位置、访问权限及时间戳等。
查看 /etc/passwd的元数据:
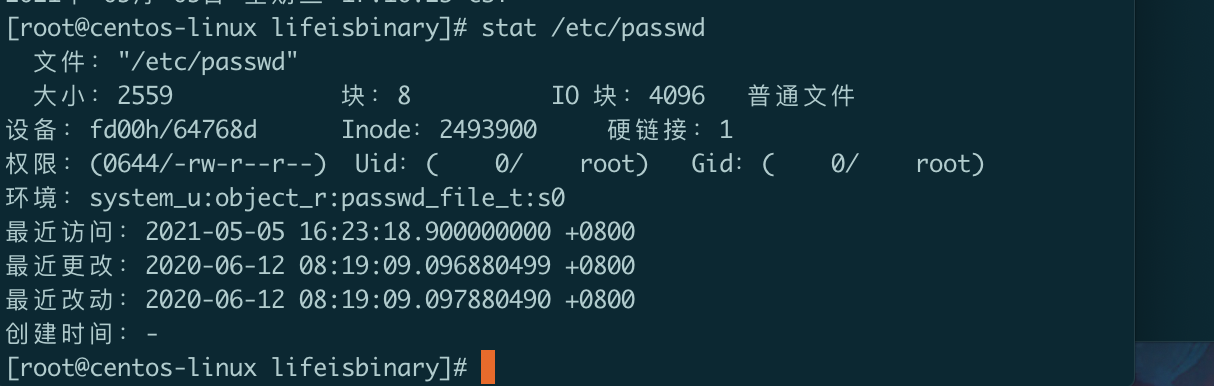
最近更改时间指的是文件内容的变化,最近改动时间指的是文件元数据的变化。而内容的变化会引起文件大小的变化,即内容变化会导致文件最近更改时间和最近改动时间的同时变化。
文件元数据单个变化包括:权限修改操作、重新命名等。
linux避免频繁对磁盘进行写入操作,一般文件的最近访问时间不会实时变化。
文件查找命令
简单快速查找——locate
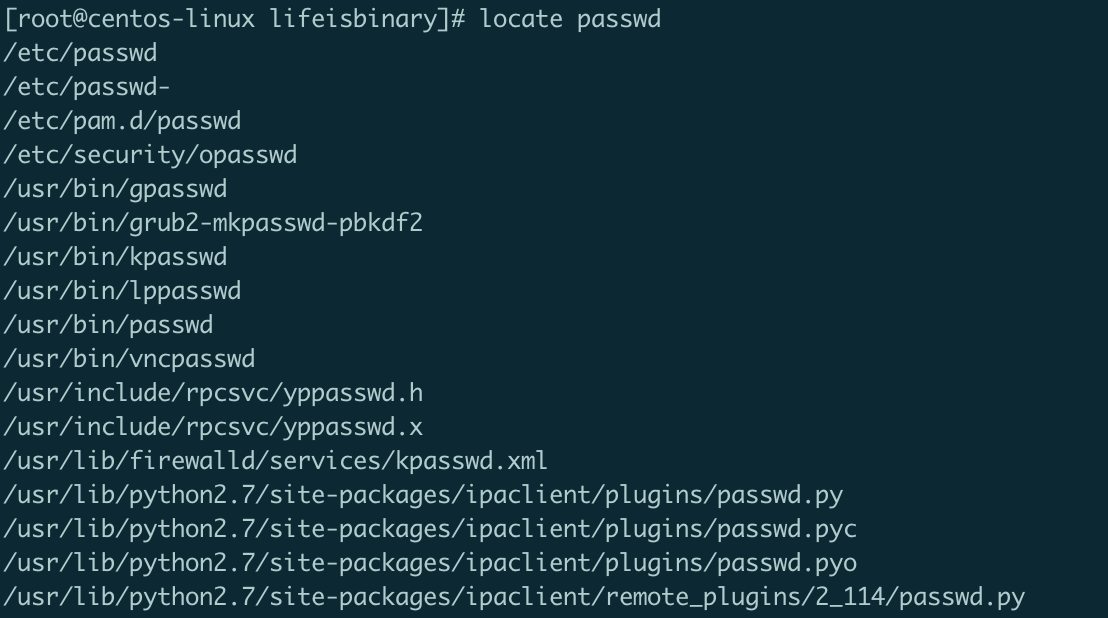
无需给定查找的起始路径,查找速度快。
locate只能实现模糊查找,如查找passwd文件,会出现很多结果。因为它会将所有的名字甚至路径中包含“passwd”的目录和文件全部查出来。
另外,它是基于实现构建的索引数据库,该数据库定期更新。因而lacate无法查找刚刚新建的文件。
强大的文件查找命令——find
能够实现精确的查找
find [查找路径] [选项] [查找条件] [处理动作]
查找条件:可以根据文件名、文件大小、文件类型、从属关系和权限等进行设置
处理动作:对查到的文件要执行的操作。如复制、删除等。
查找条件设置:
find /etc -name "net*.conf" //按名称查找,允许使用通配符
find /etc/ -iname "*net*" //按名称查找,不区分大小写
find / -empty //查找空文件和空目录
find /etc -type l -ls //查找链接文件,并显示其详细信息
find /etc -size +1M //查找大小在1M以上的文件
find /etc -size -10K //查找大小在10K一下的文件
find /boot -not -type f -ls //查找所有文件类型不是普通文件的文件,并显示其详细信息
find /tmp -atime +7 -type f //查找7天内没有被访问过的文件
find /etc -mtime -1 -type f //查找最近一天之内被改动过的文件
find /etc -cmin -180 -type f //查找最近3
小时内被修改过状态信息的文件
-atime, -mtime , -ctime —— 访问时间,更改时间,改动时间
-amin, -mmin, -cmin类似
-exec ,对查到的结果进一步处理
find /boot -name "init*" -exec cp {} /tmp \
“{}”:表示find查询到的结果
“\“:命令结束的标志
同时指定多个查询条件
find /boot -size +1024K -name "init*"
find的辅助命令——xargs
find查询后的结果可能很多,如果都送入exec的执行命令中,可能由于结果太多,命令无法处理这么多的参数。因此使用xargs分批将结果传给后续的命令进行处理。
find /tmp -name "*.txt" -exec cp {} /root \
find /tmp -name "*.txt" | xargs -i cp {} /root
如果 -exec命令不满足要求时,使用xargs命令。
linux内部命令和外部命令
内部命令:集成在shell中的命令,只要shell被执行,内部命令就
自动载入内存,用户可以直接使用。
外部命令:考虑到运行效率等原因,不可能把所有的命令都集成在Shell中,更多的linux命令是独立于Shell之外的,这些命令成为外部命令。
使用
type 命令名可以查看命令是外部命令还是内部命令
linux中的大部分命令属于外部命令,而每个外部命令都对应了系统中一个可以执行的二进制文件,这些二进制文件主要存放在下列目录中:
- 普通命令: /bin, /usr/bin 和 /usr/local/bin
- 管理员命令(root权限执行): /sbin , /usr/sbin 和 usr/local/sbin
使用
which 命令名可以查看外部命令对应的程序文件,which的搜索范围由环境变量PATH决定。
Linux系统默认将外部命令文件的存放路径保存在一个名为PATH的环境变量中。
当用户输入命令并执行时,Shell首先会检查命令是否是内部命令,若不是,Shell就会从PATH变量所保存的这些路径中寻找命令所对应的程序文件。如果把一个外部命令对应的程序文件删除,或者存放外部命令程序文件的目录没有被添加到PATH变量中,这会导致外部命令无法正常执行。
Linux会将用户执行过的外部命令的程序文件路径缓存下来,这样再次执行时,就不需要去PATH中查找。使用hash命令可以查看当前Shell所缓存的命令程序文件路径。
常用命令设置别名——alias
alias //查看当前系统中存在的别名
alias cpd='cat /etc/passwd' //设置查看密码文件的命令别名
unalias cpd //删除别名
注意:设置的别名只在当前Shell有效。 如果需要在每次用户登录后都有效,需要将该命令写入到配置文件中。
希望对所有用户有效,写入全局配置文件 /etc/bashrc
希望对指定用户有效,写入相应用户的家目录中 ~/.bashrc
修改完配置文件后,需要通过 source 配置文件,才能够立即生效
查看执行命令的历史记录——history
history 3 //列出最近执行过的三条历史命令
history !16 //把第16条历史命令重新执行一遍
history -d 16 //删除第16条历史命令
history -c //删除缓存中的历史命令
查看命令帮助信息——help
内部命令帮助信息查看——help 命令名
外部命令帮助信息查看——命令名 --help
help查看的帮助信息较为简略,如果要查看更为详尽的帮助信息,可以使用
man 命令名命令。无论是外部命令还是内部命令,都可以使用man
清屏——clear
快捷键——ctrl + L
标准输入输出
linux系统中一切皆文件,因此负责输入和输出的硬件设备也被视为系统中的一个文件。用户在通过操作biotin给处理信息的过程中,包含一下三类交互设备:
- 标准输入(stdin):默认是键盘,文件描述符为0。从标准输入文件中读取数据
- 标注输出(stdout): 默认是显示器,文件描述符为1。输出数据到标准输出文件中。
- 标准错误(stderr):默认是显示器,文件描述符为2。输出错误信息到标准错误文件中。
一个linux程序通常从标准输入中得到输入数据,并将正常数据输出到标准输出,将错误信息输出到标准错误。
在某些情况,我们可能希望从键盘以外的其他设备读取数据,或者将数据送到显示器以外的其他输出设备,这种情况就成为重定向。
Shell中,输入重定向能够把文件导入命令中,输出重定向能够把原本输出到屏幕的信息写入指定文件中。
管道则为输入和输出重定向的结合,一个程序向管道的一端发送数据,而另一个程序从管道的另一端读取数据,即“把前一个命令原本要输出到屏幕的数据当作后一个命令的标准输入”。管道为不同命令的协同工作提供了一种机制。
重定向
标准输出重定向
cat /etc/passwd > pass.txt//输出重定向 (覆盖)tail -3 /etc/shadow >>pass.txt//输出重定向(追加)cat 1.txt 2.txt > 3.txt//两个文本合并到一个文本cat 1.txt > 2.txt//将文本的内容复制到另一个文本(覆盖)cat 1.txt > 2.txt//将文本的内容追加到另一个文本标准输入重定向
将命令接受输入的途径从默认的键盘改为指定的文件
cat >test.txt <<EOF//将一段连续输入的信息保存至指定文档。通过EOF结束连续的输入,结束标记必须要在最后一行的行首顶格书写。标准错误重定向
将命令执行过程中的错误信息重定向并保存到指定的文件中
find / -user student 2> find.txt//将错误信息保存到find文件中, “2>”中,2是标准错误输出的文件描述符。find / -user student &> find.txt//将程序运行的结果(正确执行的信息或错误信息)保存到find中 ,“&>”用来合并正常输出和错误输出。linux系统中提供了一个特殊的设备文件/dev/null,被称为“黑洞”设备文件,进入该设备的数据将被“吞并”而丢失。
在有些命令执行过程中会产生一些错误信息,而我们不关心这些错误信息,只想看到正常执行的结果,可以通过标准错误重定向到/dev/null,来过滤这些错误信息。
find / -user student 2> /dev/null//过滤错误信息cat /dev/null > test.txt// 利用黑洞设备文件清空一个文件内容管道符 |
可以把多个命令连接起来实现复杂的功能
管道符左侧命令的结果将作为右侧命令的输入
ls -lh /etc | grep net列出/etc目录下包含net关键字的目录和文件head /etc/passwd | tail -1从paawd文件中取出第10行
Vi文本编辑器
Visual Interface
vim是vi的增强版
vim [filename]
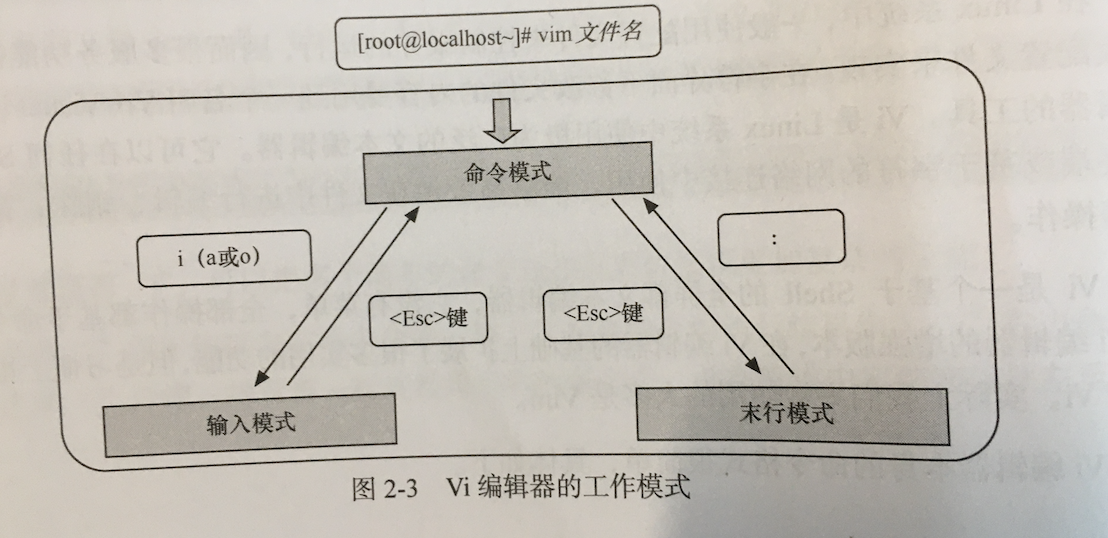
- vi编辑器的三种模式:
- 命令模式:启动后默认进入命令模式,主要完成光标移动、字符串查找、删除、复制和粘贴等操作。无论用户处于何种模式,通过
键都可以进入命令模式 - 插入模式:在命令模式下,输入 i可以切换到插入模式。该模式主要就是文本内容编辑,修改、删除或添加。处于插入模式时,vi编辑器的最后一行会出现“–INSERT–“的状态提示信息。
- 末行模式:在命令模式下,输入:即可进入末行模式,可以保存文件、退出文件编辑,对文件内容进行查找、替换等。当处于末行模式时,vi编辑器的最后一行会显示:提示符
- 命令模式:启动后默认进入命令模式,主要完成光标移动、字符串查找、删除、复制和粘贴等操作。无论用户处于何种模式,通过
vi的常用命令
命令模式下
光标移动:
翻页: Ctrl+F (向下翻页) Ctrl+B(向上翻页)
行内跳转:
0 或者 ^(跳转至行首) $ (跳转至行尾)
6 右方向键 (向右移动6个字符) 6 左方向键 (向左移动6个字符)
行间跳转:
gg 跳转至首行 G跳转至尾行
6G 跳转至第6行
行号显示: :set nu(vi中显示行号) :set none (vi中取消行号)
复制、粘贴和删除
- x 删除光标处的单个字符 dd 删除光标所在的行
- yy 复制当前光标所在行的内容 p 粘贴内容到光标所在行之后
文件内容查找
- /xxx 自上而下查找字符串 ?xxx 自下而上查找字符串 (n 定位下一个搜索匹配的结果,N定位上一个搜索匹配的结果)
撤销编辑: u 撤销最近的一次操作,默认情况最多可以撤销50次 Ctrl+R 恢复最近一次的操作
末行模式下
保存文件: :w保存 :w ~/Desktop/newfile 另存为其他文件
退出: :q未修改退出 :q! 放弃修改退出
保存并退出: :wq
文件内容替换: :% s/旧内容/新内容【/gc】
g每行的所有匹配结果都替换,默认只替换每行匹配的第一个结果 c表示每次替换都进行询问
vi的可视模式
在命令模式下 ,v 进入按字符选定内容,y进行复制,d进行删除,p进行粘贴。可视模式提供了一种更加简便的对部分字符进行复制、删除等操作的处理方式。
vi编辑器提供的官方联系教程,命令行输入
vimtutor
软件包管理
linux的软件安装主要分为:
源码安装方式:
困难且耗时的方式。在取得源码后,需要编译并解决软件依赖关系。在安装和卸载时,需要考虑软件与其他程序、库的依赖关系,操作难度较大。
源码安装的优势:
- 可移植性好。可以安装到任何linux中使用,而RPM包只能用于某些Linux
- 可以灵活定制软件,运行效率高(编译过程可以更好的适应安装主机的系统环境,运行效率和优化程度强于使用RPM包安装)。
- 版本新。代码总是最先发布
RPM安装方式:
源码安装方式复杂耗时,RedHat公司设计了一种软件包管理系统RPM(RedHat Packet Manager)。
RPM是一种已经编译好并封装好的软件包(软件包中会封装程序、配置文件和帮助手册等),用户可以直接安装。RPM软件包是CentOS系统中软件的基本组成单位,每个软件都是由一个或多个RPM软件包组成。通过RPM,用户可以轻松的管理系统中的所有软件。
RPM软件包只能用于采用RPM机制的Linux系统上(RHEL、CentOS、Fedora、SUSE等)。RPM相较于其他的包管理机制,基本已经成为Linux系统中软件包管理事实上的标准。
RPM的一大缺点是:RPM软件包之间的依赖复杂。如安装A包需要B包的支持,而安装B包又需要C包的支持。因此,在安装A之前,必须先安装C,再安装B,最后才能安装A包。如此复杂的依赖关系都要由用户自行来解决。
YUM安装方式:
YUM在RPM的基础上,解决了RPM软件包之间的依赖问题,从而更加轻松地管理Linux系统中的软件。
从RHEL 5时代起,RedHat就推荐使用YUM软件安装方式。
linux上下载的软件安装包,一般都是 .gz、.tar.gz 和 .tgz之类的压缩文件,需要先进行解压缩。
tar命令——文件打包和压缩
linux中打包和压缩是两个分开的操作。
打包命令:tar
压缩命令:gzip、bzip2、xz
通常先进行打包,后调用某种压缩工作进行压缩。如文件名后缀为 .tar.gz 、 .tgz的文件就属于这种先打包再压缩的文件。
在实际使用中,一般通过tar命令来调用gzip进行压缩或解压,而很少单独使用这些压缩命令。
- 打包并压缩:
tar -zcvf newfile.tar.gz directory //将directory目录打包并压缩保存为newfile.tar.gz文件
- -c: 创建 .tar格式的文件,不会进行压缩
- -v: 显示打包的过程
- -f: 指定打包或者解包的文件名,必须在选型的最后一位
- -z: 指定的压缩方式为gzip
解包和解压缩
tar -xf【 压缩文件】 -C 【解压后的目录】- -x: 解开tar格式的包文件
- -f:指定解包的文件
- -C:指定解压后文件存放的位置
此命令不需要指定调用那种压缩工作,系统会分析压缩文件的格式,自动调用相应的压缩工具进行解压。
使用YUM进行软件安装
配置yum源
yum源就是存放大量RPM软件包的远程仓库
yum源通过文件的方式来配置,存放在 /etc/yum.repos.d/目录中,以.repo为后坠
访问系统本身的默认yum源,比较慢。设置阿里云的yum源。
为了避免系统中同时存在多个yun源而造成混乱,先将系统默认的yum源文件全部删除。
rm -f /etc/yum.repos.d/*。然后从阿里云镜像网站下载yum配置文件,并将其存放到系统指定的目录。
wget http://mirros.aliyun.com/repo/Centos-7.repo -O /etc/yum.repos.d/Centos-7.repo通过yum list 列出当前系统已经安装和未安装的软件包。名字前有@符号的是已经安装过的软件包。
yum list xxx查看yum源中是否有该软件包yum repolist查看当前系统中可用的yun源,也可以用于检测yum源是否配置好常用的yum命令
yum info xxx: 查看软件包的信息(版本,软件功能)。如果软件包已经安装,则会显示已经安装的软件包。如果未安装,则会显示可安装的软件包。yum install xxx安装软件包,安装过程中如果该软件包依赖的其他包未安装,则会询问用户是否安装该软件包需要的依赖包。yum install xxx -y当安装过程中进行询问时,自动确认yum remove xxx卸载软件。yum remove在卸载一个软件时同时会将所有依赖于该软件的其他软件包一同卸载。例如,yum remove cpp,cpp是安装gcc时作为依赖包被一通安装的,因而在卸载cpp时会提示将要gcc也一同卸载。因为如果cpp被卸载了,那么gcc肯定也无法正常使用。但是这也就会导致新的问题出现,比如gcc又是别的软件的依赖包,那么将会导致这些软件也无法正常使用。因此,如果这些被一同卸载的软件正好是其他软件或者系统本身运行需要的,就容易造成问题甚至系统奔溃。因而在使用yum remove命令卸载软件时一定要慎重。
yum clean all 清除本地缓存,yum会自动创建本地缓存,一条yum执行效率。yum默认优先使用yun缓存来获取软件相关信息。如果发现yum运行不正常,也许就是由于yum缓存造成的。此时就需要清空yum缓存。
yum故障排查
- 确认:yum源的定义文件是否存在错误
- 检查是否还有别的yum源定义文件,linux允许系统配置并启用多个yum源,但是必须要保证这些yum源都正确,如果其中一个出现错误,那么都会导致无法正常安装软件
- yum clean all 清空缓存
- yum list 检测是否能正确list出yum源中的软件包
RPM进行软件包管理
rpm命令在linux中主要用于查询,查询软件是否安装、查询软件包信息
RPM机制封装的软件包拥有约定俗成的命令格式: 软件名称-版本号-发布号.硬件平台.rpm

- 发布号:RPM软件包是由CentOS组织封装的,因而软件包的发布号(RedHat更新)与软件版本号(开发者更新)是两回事。
- 硬件平台:
- x86_64: 64位PC架构
- i386 / i686 : 32位PC架构
- noarch: 不区分硬件架构
安装/卸载软件
rpm -ivh rpm包的路径 安装软件包
- -i: 安装软件
- -v: 显示安装过程
- -h: 显示安装进度
rpm -e xxx 卸载软件包
查询软件包
rpm -qa | grep ssh 查看是否安装ssh
ssh 不是软件的完成名称,因此才通过 rpm -qa列出所有已经安装的软件包,再通过内容查找其返回的结果
q: qurey
rpm -qi xxx 查询已安装的软件包的信息
rpm -ql xxx 查看软件包在系统中安装的文件
一个典型的linux应用的组成:
- 普通的可执行文件,保存在 /usr/bin,普通用户可执行
- 管理程序文件,保存在 /usr/sbin,管理员权限执行
- 配置文件,保存在 /etc下,配置文件较多时,会建立子目录
- 日志文件,保存在 /var/log
- 程序的参考文档,保存在 /usr/share/doc
- 可执行文件以及配置文件的man手册, 保存在 /usr/share/man
rpm -gc xxx 查看软件包安装的配置文件
rpm -qf 文件 查询某个文件所属的软件包
which find + rpm -qf /usr/bin/find 查询find命令来自哪个软件包,如果误删了find命令文件,可以通过安装该软件包进行修复
利用源码编译安装软件
源码安装需要主机具备编译环境,C语言是Linux的标准程序语言,常见的源码包一般是用C语言开发。常用的C语言编译器是GCC。
软件在编译或者执行期间,需要依赖其他的软件或者链接库。大部分软件开发者会在README或者INSTALL文件中告知需要准备哪些软件。
源码安装的流程
解包—-配置—-编译—安装

在生产环境中,将本地的软件包传到服务器中:
在linux服务器中安装lrzsz软件,在本地的XShell中执行rz命令,这时会打开一个Windows窗口,直接选择要上传的文件即可,文件默认会被上传到当前工作目录下。
解压
一般建议将各种软件的源码统一保存到 /usr/src/ /usr/local/src/ 或 /temp/目录中,以便于集中管理。
配置
编译软件前,必须先设置好编译的参数。配置工作通常由源码中的configure脚本来完成,具体的配置参数可以在源码目录中执行 ./configure –help 进行查看
配置中有一个 –prefix参数,指定软件包安装的目标目录。源码编译安装会将软件中所有文件安装到指定的目录./configure --prefix=/usr/local/xxx。这样将来卸载软件只需要安装目录删除,而无须担心误删其他软件。
配置结果会保存到源码目录中的makefile文件中
编译
编译的过程就是根据makefile文件中的配置信息,将源码编译并连接成可执行程序。
make
make test对make的结果进行检查,保证没有错误de
安装
make install 安装过程是将软件的执行文件、配置文件等相关文件复制到linux系统的相应位置。
安装完成后,进入安装目录下的bin/sbin目录中,执行相应的程序,就可以使用安装好的软件了。
进程和服务管理
进程:系统中正在运行的程序。
服务:系统启动后自动在后台运行的程序
进程
在系统运维过程中经常设计对进程的管理操作。
进程是正在运行的程序,占用CPU和内存等资源。
进程是分配和调度操作系统资源的基本单位。
进程的状态
进程在启动后不一定立马开始运行,因而进程存在多种状态
- 理论上进程的状态
运行态:值当前进行已经分配CPU,正在处理器上执行。运行态的进程不能超过cpu的数量。
就绪态:已经具备运行的条件,但是当前的CPU被其他程序占用,等待分配CPU状态。
阻塞态:进程因等待某种事情的发生(IO输入输出完成),而不能运行。即使CPU空闲,阻塞态的该进程也不能运行。当阻塞态进程等待的时间发生之后,就会进入就绪态。
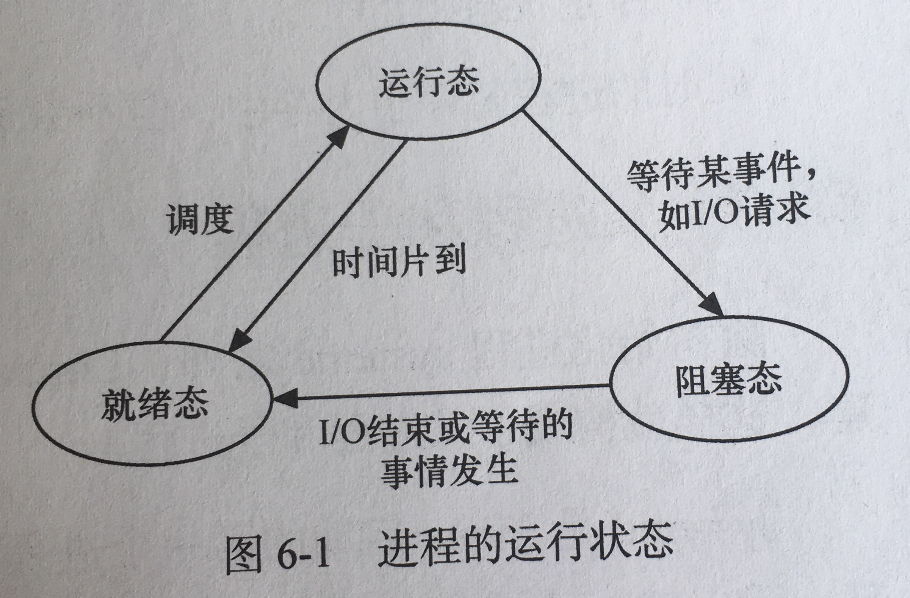
Linux系统中进程的状态
可运行状态(R): 该状态的进程,要么正在运行,要么正准备运行。理论上,运行态和就绪态的进程,在linux系统中都被视为可运行状态。
睡眠状态: 进程处于阻塞状态,一旦等待的事情完成,就会变为就绪态。
- 可中断睡眠状态 (S)
- 不可中断睡眠状态(D):处于该状态的进程对于中断信号不作出响应
僵尸状态(Z):进程执行结束,但是进程所占用的系统资源未释放。一般情况下,子进程由父进程结束,并释放其所占用的系统资源。当某个进程已经运行结束,但是它的父进程还没有释放其系统资源时,该进程就处于僵尸状态。
停止状态(T): 进程暂停于内存中,不会被调度,等待某种特殊处理。
父进程和子进程
除初始化进程systemd之外,Linux中的每个进程都必须由已经运行的进程来创建,这就就构成了父进程和子进程的关系。
systemd是Linux启动的第一个进程,系统中其他所有进程都是systemd进程的子进程。除了systemd之外,每一个进程都必须有一个父进程。父进程和子进程之间的关系是管理和被管理的关系。当父进程终止时,子进程也随之而终止,但子进程终止,父进程并不一定终止。
如果父进程在子进程结束之前就退出,那么它的子进程就变成了“孤儿”进程。如果没有相应的处理机制的话,“孤儿”进程就会一直处于僵尸状态,资源无法释放。此时解决的办法是在已启动的进程中寻找一个进程来作为这些“孤儿”进程的父进程,或者直接让systemd进程作为它们的父进程,进而释放“孤儿”进程占用的资源。
进程的属性
进程在启动后,系统会为每个进程分配一个唯一的进程标示符,称为进程ID(PID)
pidof sshd 查看sshd进程的PID
除了systemd进程的PID固定为1,其他的进程的PID都是不固定的。当进程启动时,系统会自动为其分配一个PID,当进程结束时,系统会回收这个PID。
其他属性:
- 父进程的ID (PPID)
- 启动进程的用户名 (UID)
- 进程的状态
- 进程的执行优先级
- 进程所在的终端名
- 进程占用的资源大小
进程的分类
系统进程: 能执行内存资源分配和进程切换工作,这些进程不受用户的干预,root用户也不能干预系统进程的运行
用户进程: 执行应用程序或内核之外的系统程序而产生的进程。此类进程可以在用户的控制下运行或关闭。我们管理的主要是这类用户进程。用户进程又可以分为:守护进程和交互进程
- 守护进程:由运行各种服务所产生的进程,一般在系统后台运行,而且通常会随Linux系统的启动而启动,在系统关闭的同时终止。守护进程始终是运行着的,一般其所处的状态是等待处理请求任务。例如,无乱是否有人访问Web服务器上的网页,该服务器上的httpd服务都是一直在运行。
- 交互进程:通过终端命令启动的进程,可以运行在前台也可以运行在后台。
进程状态查询——ps (process state)
ps 显示当前用户在当前终端所启动的进程
- TTY:为终端。每个终端都有相应的编号,tty 可以查看当前用户所在的终端。
echo hello > /dev/pts/5 - TIME: 只进程占用额CPU时间,通常很小,显示为0
ps aux
参数:
a:显示与当前终端有关的所有进程,包括其他用户的进程
u:显示与当前终端无关的所有进程,a和u一起使用,显示系统中的所有进程。
x:以面向用户的格式显示进程信息
执行结果:
- USER:启动该进程的用户。存在一些进程的启动者是专门的程序用户。
- VSZ:进程占用的虚拟内存集的大小,单位是KB
- RSS:进程常驻内存集的大小,单位是KB
- TTY:启动进程的终端,如果显示?,表示该进程由系统内核启动,与终端无关。
- STAT:进程的状态。 有很多辅助表示进程状态的符号: + ——前台进程,l——多线程进程,N——低优先级进程,<——高优先级进程,s——该进程是绘画领导者,如果这样的进程关闭,那么由该进程所派生出来的子进程也将被关闭。
- TIME:进程从启动以来占用CPU的总时间
- COMAMDN:启动该进程的命令。如果名称带有中括号,则表示该进程由系统内核启动
因为ps aux 显示的内容多一般与more连用
ps -ef
- -e:显示系统中所有进程的信息
- -f:显示进程的所有信息
结果:
- C:进程所占用的CPU百分比
该命令,可以显示进程的父进程ID
top——查看进程的动态信息

top命令结果:
第一行:系统时间,系统启动的时间,当前登录系统的用户个数,CPU的负载情况:过去1min,过去5min,过去15min
第二行:进程总数,各状态的进程数
第3~5:cpu的使用情况、内存使用情况,交换分区使用情况
在top命令执行期间,可以对显示的结果进程排序。
P键——按占CPU的百分比排序(默认)
M键——按占内存的百分比排序
T键——按占用CPU的时间排序
N键——按进程启动时间排序
伪文件系统—— /proc
/proc被称为伪文件系统,因为该目录存放的并不是传统意义上的硬盘中的文件或目录,而是内存中正在运行的数据。
系统中所有进程的状态信息以文件的形式被存放在该目录中。
/proc目录中有很多以数字命令的目录,这些数字其实是进程PID,每个进程的信息都保存在对应的目录中。ps 和 top 命令都是从/proc目录获取进程的状态信息
进程控制
在shell命令行中执行某条命令,启动的进程默认情况下属于前台进程。执行过程中产生的相关信息会显示在终端上,进程执行过程中会占用当前终端,进程没结束,用户不能在当前终端执行其他操作。
在要执行的命令后面加上&符号,则此进程转到当前终端后台运行。后台启动适合那些运行期间不需要用户干预或执行时间较长的程序。
jobs -l // 查看当前终端中正在后台运行的进程任务
进程的前后台执行切换:
后台进程切换到前台
fg(frontground)命令,将后台进程切换到前台
fg 1将任务编号为1的后台进程切换为前台执行前台进程切换到后台
Ctrl + Z 切换到后台,进程处于停止状态
bg(background)命令,让后台挂起的进程继续执行
通过shell运行的进程,无论是后台进程还是前台进程都与当前终端有关。如果关闭终端,那么该终端所有的进程也会关闭。这所以这样,是因为当前终端是所有其中运行的进程的父进程,它是一个回话的领导者,所以只要关闭它,终端中所有的子进程自然也会被关闭。
通过nohop命令可以解除要执行的命令与当前终端之间的关系,使启动的进程为系统的后台进程。
nohop nc -lp 9527
终止进程
前台进程——Ctrl+C
后台进程——fg 切换到前台——Ctrl+C
其他终端或系统后台运行的进程——kill命令
kill命令:
kill PID
kill命令通过向进程发送终止信号使其退出运行。
kill可以发送的信号有多种,每个信号都有一个编号。其中默认使用的是15号信号SIGTERM。若进程已经无法响应终止信号,那么可以发送9号信号SIGKILL,强行将进程终止(kill -9 PID)。
killall命令终止一组进程,通过程序的名字,直接结束所有进程。
killall sshd 客户端与服务器之间的所有连接都将被断开。
lsof(list open files)
查看当前系统文件的工具。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。如传输控制协议 (TCP) 和用户数据报协议 (UDP) 套接字等,系统在后台都为该应用程序分配了一个文件描述符,该文件描述符提供了大量关于这个应用程序本身的信息。
lsof -i:端口号 //查看占用某端口的进程
查看用户登录信息
linux是一个多用户的操作系统,在同一时间可能会有多个用户同时登录使用系统,可以通过users、who或者w命令查看当前有哪些用户正在登录系统
users //列出当前所有登录该系统的用户名
who //列出当前所有登录该系统的用户信息(用户名、终端、登录时间以及源IP地址)
w //who命令的增加版,除了who命令列出的信息,还可以列出用户正在执行的命令
last //查看系统的登录记录,哪些人以什么身份在什么终端上登录本机。由于last命令是通过查询日志文件来获取登录信息,而日志文件又容易被黑客篡改,因此不能单纯以该命令的输出信息来判断系统有无被恶意入侵。
踢出可疑用户
通过who查到用户的终端——通过ps aux | grep pts/0查到终端进程的PID——通过kill -9 PID强制终止该进程
查看系统占用的资源情况
cat /proc/cpuinfo //查看系统CPU硬件信息
uptime //查看CPU使用情况, top命令的第一行信息
free -h -s 10 //查看内存使用情况,-h:人性化显示内存容量单位,-s 动态刷新信息的时间频率,秒为单位
avilabel表示的系统可用内存大于free的值,是因为加入了buff/cache的部分可以回收的内存空间
du -hs [directory] //查看某个目录的大小
服务
服务:
在系统后台运行,等待用户或其他软件调用的一类特殊程序。无论在哪个终端上运行服务,该服务所产生的进程都与终端无关,也就是说,将终端关闭之后,这些服务进程仍然会在系统后台自动运行。
Linux系统中服务名称的最后一般带有字母d,如vsftpd、httpd、sshd等,d是英文单词daemon的缩写,表示这是一种守护进程。
系统初始化进程
初始化进程是Linux系统启动时第一个被执行的进程,它负责启动并管理其他各种服务,完成系统的初始化工作。
CentOS 7 的初始化进程是systemd。sytemd由系统自动在后台运行,所以也是一种典型的服务,一般也称systemd服务。systemd的PID永远为1。systemd进程启动后将陆续运行系统中的其他程序,不断生成新的进程。这些进程称为systemd的子进程,这些子进程可以进一步生成各自的子进程,最终构成一颗进程数。因此,systemd进程是维持整个Linux系统运行的所有进程的基础,该进程是不允许轻易终止的。
pstree 可以显示系统的进程数。
在CentOS 7之前的版本中,采用的初始化进程是init,从CentOS 7开始采用systemd初始化进程。systemd相比于init的优势:
- 开机速度变快。在系统开机的时候,systemd可以并发启动一些没有依赖的服务。不需要向init那样,让服务一个一个的排队,一个一个启动。
- systemd提供按需启动服务的功能。在init初始化的时候,会将所有可能用到的服务全部启动起来,系统必须等待所有服务都启动就绪后,才允许用户登录。systemd只有在某个服务被真正请求的时候才启动它,当该服务结束时,可以动态关闭它,等待下次需要时才会再启动。
systemd中有一个核心的概念unit,systemd的系统管理功能主要就是通过各种unit来实现的。每中unit都有一个相应的配置文件对其进程标识和配置。这些配置文件主要存放在 /usr/lib/systemd/system/ 和 /etc/systemd/sytem/目录下。
- 对服务进程管理的单元Service unit:以.service结尾。系统中每一种服务都会有一个与之对应的服务单元。
- 目标单元Target unit:以.target结尾。用于模拟实现系统运行级别。
- 设备单元Device unit:定义系统内核需要识别的设备
- 挂载单元Mount unit:定义文件系统的挂载点
使用systemctl命令管理服务
Linux系统中提供了很多服务,从功能上可以分为:系统服务和网络服务。我们要管理的主要是网络服务(提供远程登录的sshd服务,提供网站浏览的httpd服务)。
CentOS 5和CentOS 6系统中,对服务的管理主要是通过service和chkconfig命令完成,在CentOS 7中则主要是通过systemctl,systemctl是systemd提供的一个重要管理工具。
systemctl start|stop|status|restart|reload 服务名
systemd将系统中的每个服务都看作一个服务单元(Service unit),在服务的名称后面加上.service作为后缀。在利用systemctl命令对服务进行管理时,服务名称后面加不加.service后缀均可。
system status xxx
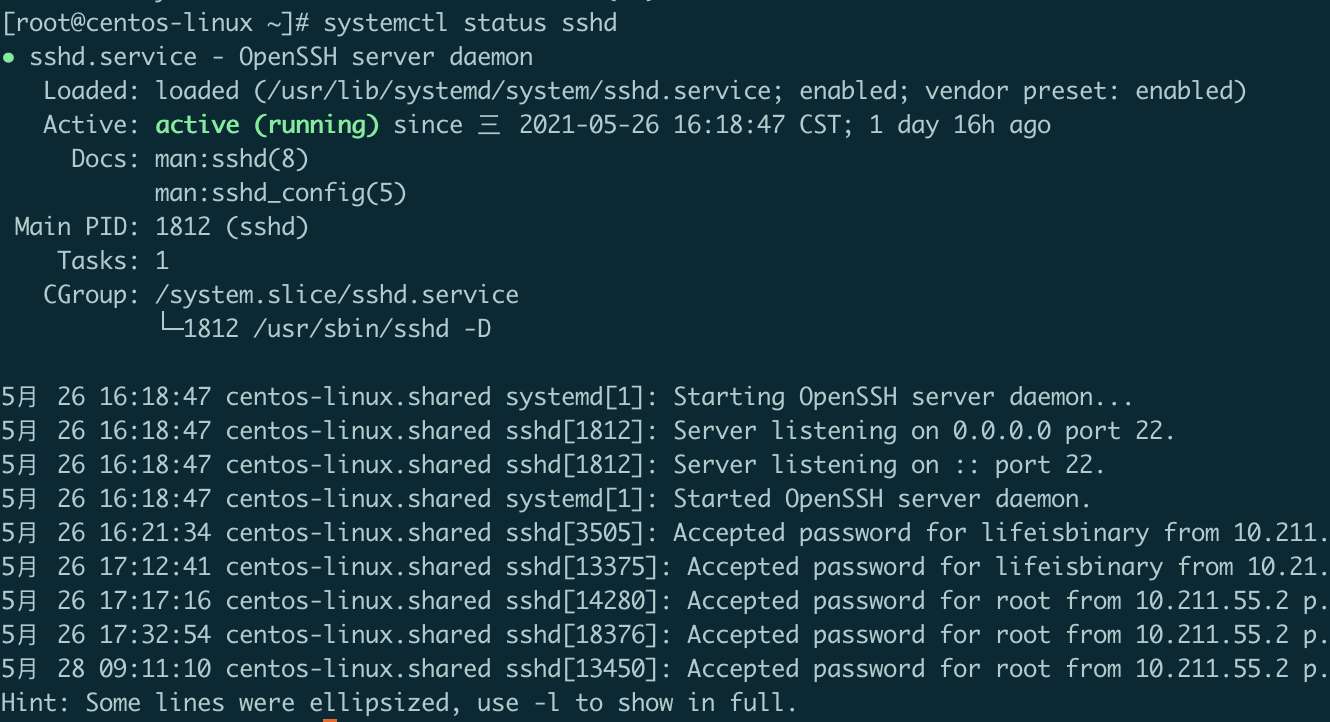
结果解释:
第二行:表示服务已经被加载,该服务的Service unit配置文件位置,enabled表示服务已经被设为开机自动启动,vendor preset:enabled 表示该服务在系统中默认被预设为开机自动启动。
在服务的配置管理中,如果修改了某项服务的设置,那么必须将服务重启,才能使得修改后的配置生效。
systemctl restart xxx
restart的重启方式会使服务产生暂时的中断,如果需要在不中断服务的前提下使得修改后的配置设置生效,需要使用reload方式重新加载服务。但对于某些服务配置所做的修改,必须重启才能生效,比如修改服务的端口号等网络配置,就无法通过reload方式重新加载。
systemctl list-units --type service 查看系统中所有正在运行的服务
systemctl list-units --type service --all 列出系统中所有的服务
systemctl enable|disable|is-enabled 服务名
- enable 设置服务为开机自动启动
- disable 表示禁止服务开机自动启动
- is-enabled 查看服务的启动状态
systemctl list-unit-files --type service 查看系统中所有服务的开机启动状态
Linux上安装并使用一个服务的基本操作:
- 查询系统中是否安装该服务
rpm -qa | grep xxx - 安装该服务
yum install xxx -y - 启动服务
systemctl start xxx - 设置开机自动启动
systemctl enable xxx
管理系统的运行级别
Window中,正常启动模式和安全模式下,所能够运行的程序有所不同。正常模式下,所有被设为开机自动运行的服务或程序都会被自动启动,但如果进入安全模式,那么就只会启动系统基本的程序以及微软官方的服务。Linux中也有类似的机制,它将在系统运行时启动的各种程序服务互相组合以构成不同的搭配关系,满足不同的系统需求。这种搭配关系称为“运行级别”。总共有7种运行级别(0~6)。
不同的运行级别代表系统不同的运行状态,每种运行级别下所运行的服务或者程序会有所区别。
常用的运行级别时3和5,代表字符模式和图形模式。在选择相应的运行级别后,系统在启动时运行的服务就会有所区别。
将运行级别设置为3,系统启动时将会自动进入字符模式,所有与图像界面相关的服务都不会运行。
将系统级别设置为5,系统启动时会自动进入图形模式,自动运行与图形模式相关的服务。系统安装了图形界面,默认运行级别是5。
在CentOS 5 和 CentOS 6系统中对运行级别进行管理,主要是借助runlevel 和 init 命令,CentOS 7也支持这两种命令。但是更加推荐使用systemctl命令。
systemctl get-default 查看系统的默认运行级别
runlevel 查看系统的运行级别,结果会显示,上次切换前的系统(如果为N 表示之前未切换过运行级别)级别 和当前的系统级别
init 3 切换到运行级别3模式,字符模式
init 0 关闭系统
init 6 重启系统
以上的方式切换系统级别只是临时的,当系统重启后,还是会进入默认的运行级别。
systemctl set-default multi-user.target // 设置系统的默认运行级别为3
systemctl set-default graphical.target // 设置系统默认运行级别为5
重置root密码
Window系统重置管理员密码:
- 用引导盘启动系统并进入WinPE
- 利用WinPE中提供的密码修改工具
Linux系统:
CentOS 5 和 CentOS 6:
- 启动系统进入单用户模式(运行级别1),此时无需密码即可以root身份登录系统
- 然后修改root用户密码
CentOS 7:
1. 进入救援模式,类似WinPE
2. 密码重置
无论是单用户模式还是救援模式,都只能在系统本地登录才能使用,而无法通过网络远程操作,这样设计的目的很明显是处于安全的考虑。
计划任务
计划任务可以让系统在指定的时间自动执行预先计划好的管理任务,因而计划任务是实现Linux系统自动化运维的重要途径。
通过计划任务来执行需要在指定时间或周期性执行的操作。
对于那些比较费时间而且占用资源较多的操作,可以通过设置计划任务,将它们安排在深夜由系统自动运行,从而避免影响正常服务的运行。
Linux系统听过两种计划任务:只会执行一次的at计划任务 和 可以周期执行的cron任务
执行一次的at计划任务
在确认atd服务已经运行的情况下,
at 计划的时间命令进入交互模式,一次输入准备执行的命令,最后按Ctrl+D保存。计划时间的格式:
- HH:MM [YYYY-mm-dd]:
at 10:05或at 10:05 2018-12-28 - tomorrow:
at 10:05 tomorrow
到时间后,系统会自动执行计划任务中的相关命令,并将执行结果以邮件的形式发送给用户。用户再此登录时,会看到友新邮件提示,执行mailx命令可以查看邮件。
at -l查看等待执行的计划任务at -c 2查看编号为2的计划任务的具体内容at -d 2删除编号为2的计划任务- HH:MM [YYYY-mm-dd]:
通过非交互方式创建计划任务,
echo 'systemctl restart http' | at 23:00
配置cron周期性计划任务
更多情况下,我们可能需要周期性地执行某项操作,比如每天凌晨2:00自动将/etc目录进行打包备份。
crontab命令用来设置用户的周期性计划,执行该命令会生成一个以用户名命名的配置文件,存放在/var/spool/cron目录中。
crontab -e编辑计划任务列表,打开一个任务编辑的界面。每一行代表一个记录,每个记录包括六个字段。
在时间周期设置中,没有设置的位置要用*号占位。
在配置计划任务时,命令建议使用绝对路径,因为当前系统执行计划任务中的操作时,无法获取环境变量PATH中保存的路径。关于命令的绝对路径,可以使用which查看
配置计划中的重点和难点是时间周期的设置

0 23 */5 * * /usr/bin/rm -rf /var/ftp/pub/* 每隔5天,在23:00清空一次FTP服务器公共目录 /var/ftp/pub中的数据
30 17 * * 1,3,5 /usr/bin/tar -zcf httpd.tar.gz /etc/httpd 每周1,3,5的17:30,使用tar自动备份/etc/httpd目录
crontab -e -u lifeisbinary 为lifeisbinary用户设置计划任务
crontab -l 查看用户计划任务
crontab -l -u lifeisbinary
crontab -r -u lifeisbinary 删除用户lifesibinary的计划任务
删除单条任务使用 crontab -e
使用 crontab 命令设置的是用户计划任务,除此之外,用户还可以通过编辑/etc/crontab文件,设置系统计划任务。
配置系统任务时,应遵循“分钟 小时 天 月 星期 用户 命令“的格式。
0 */3 * * * root /usr/bin/echo "hello world"
磁盘和文件系统管理
磁盘分区和格式化
磁盘分区
传统的磁盘分区包括:主分区、扩展分区、逻辑分区3中。
硬盘的主引导扇区(MBR)中用来存放分区信息的空间只有64个字节(主引导扇区一共只有512字节空间),而每个分区的信息要占16个字节,因而理论上一块磁盘最多只有4个分区,这四个分区都是主分区。
硬盘越来越大,4个分区远远不够,引入扩展分区的概念。扩展分区也是主分区。但它不能直接使用,相当于一个容器。在扩展分区中可以创建新的分区,这些分区被称为逻辑分区。逻辑分区的数量不再受主引导扇区空间大小的限制,想SCSI或SATA接口的磁盘在Linux系统中最多可以创建12个逻辑分区。
Linux系统中,所有磁盘和磁盘中的每个分区都是用文件的形式来表示。例如,在计算机中有一块硬盘,硬盘上划分了3个分区,那么在Linux系统中就会有相对应的4个设备文件,一个是硬盘的设备文件,另外每个分区也有一个设备文件,所有的设备文件都统一存放在/dev目录。
不同类型硬盘和分区的设备文件都有统一的命名规则。
- 硬盘:对于SATA或SCSI接口的硬盘设备,采用“sdX”的文件名,其中X为a,b,c,d等字母序号。例如,系统中的第一块硬盘表示为“sda”。
- 分区:以硬盘设备的文件名作为基础,在后边添加该分区对应的数字序号。例如,第一块硬盘中的第一个分区表示为“sda1”。
主分区数目最多为4,因此主分区和扩展分区的序号限制为1~4。逻辑分区的序号将从5开始。第一个逻辑分区的序号为“sda5”。
文件系统
文件系统,决定了磁盘分区中存放、读取文件数据的方式和效率。
对于一块新的磁盘,在向其存放数据之前,必须先创建文件系统。文件系统是在对磁盘分区进程高级格式化时被创建的,在系统中会存在很多不同类型的文件系统。
Windows下,磁盘分区通常采用FAT32或NTFS。
Linux下,常用EXT系列和XFS文件系统。在CentOS 7之前,采用EXT系列,从CentOS 7开始转向更适合大数据环境的XFS。
Linux系统也可以支持Windows中的FAT32文件系统,在Linux中该文件系统名称换为VFAT。
Linux系统不支持NTFS,在Linux上使用NTFS硬盘,需要额外安装NTFS-3G软件包。
文件/etc/filesystems中存放了系统支持的所有文件系统类型。
Linux中有一个swap类型文件系统——交换分区。类似于Windows的虚拟内存。
分区管理
Linux中,磁盘分区管理工具是fdisk。
fdisk -l
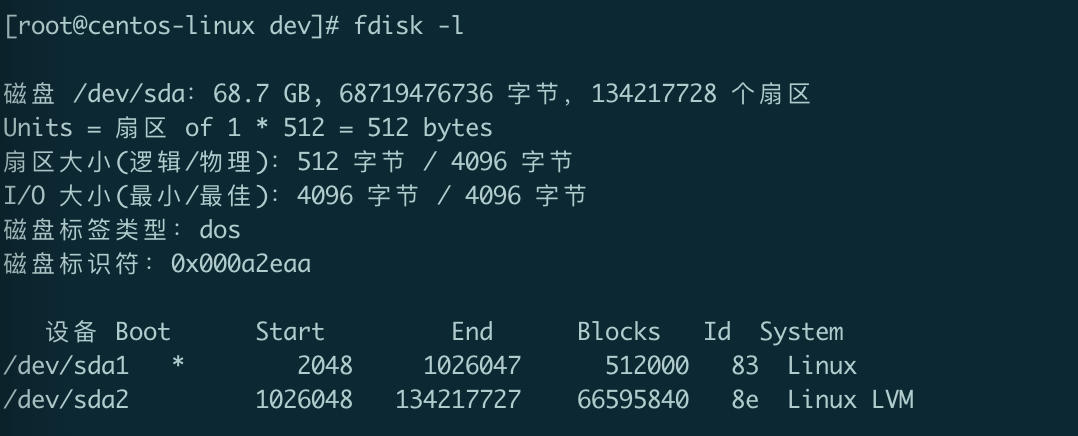
- Boot: 是否是引导分区,* 表示引导分区
- Id:表示分区类型的ID标记号,对于XFS分区,其为83,对于LVM分区,其为8e
- System:表示分区类型,Linux代表XFS文件系统,Linux LVM代表逻辑卷
添加新硬盘给机器
fdisk -l
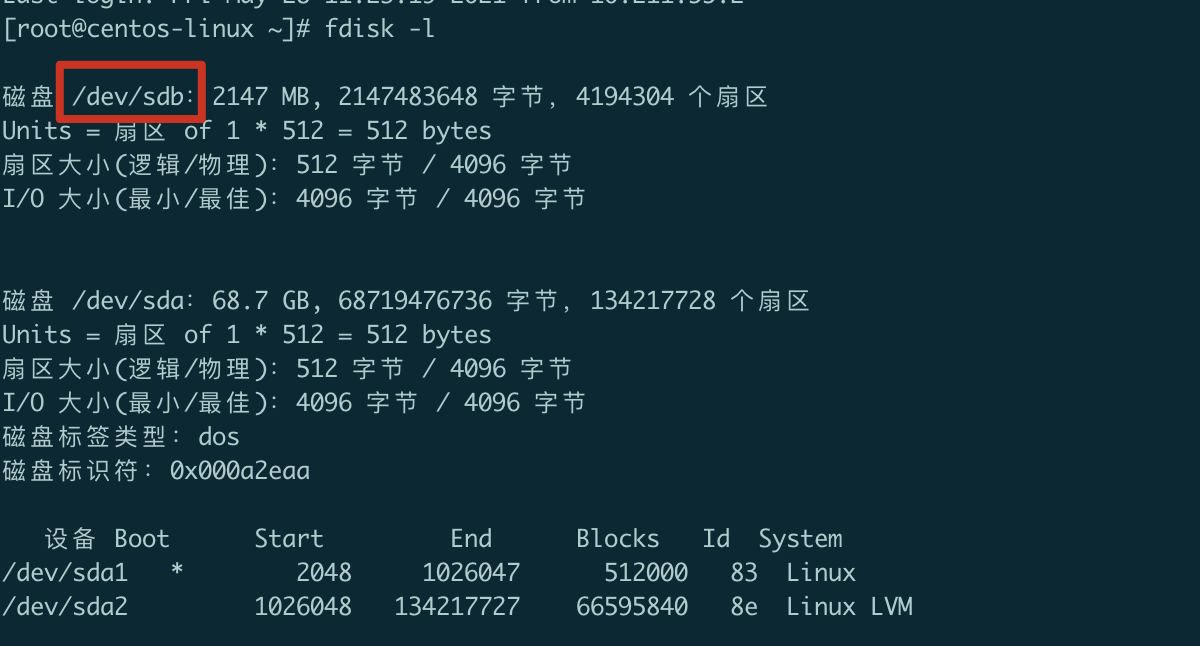
新加的硬盘为初始化,名称没有有效信息
分区:
fdisk /dev/sdb进入磁盘分区的交互界面。在创建逻辑分区前,需要先创建其容器扩建分区。
分区删除可以在fdisk交互界面中使用d。
格式化分区:
格式化的主要目的是在分区中创建文件系统,同时格式化也会清空所有数据。
mkfs -t 指定的文件系统 分区设备文件名mkfs -t xfs /dev/sdb1挂载
Linux系统与Windows系统在存储设备操作方式上的一个非常重要的区别就是挂载。
在Linux系统中,核心系统虽然可以通过设备文件操作各种设备,但是对用户来说,还需要通过挂载,才能想正常访问目录一样访问存储设备中的资源。
挂载就是将用户不方便操作的设备文件与系统中的目录绑定起来,这样用户可以通过访问目录,来调用里面的数据。
作为挂载点的目录必须事先存在,挂载点目录最好为空目录,否则挂载之后,目录原有的内容会被暂时隐藏。
mount 设备文件 挂载点目录umount 挂载点目录//必须保证此时存储设备不能处于busy状态,常见的错误是在挂载点下进行卸载操作。Linux系统提供了两个默认的挂载点目录:/media 和 /mnt
- /media 系统自动挂载点,在图形界面下,插入U盘或光盘时,系统会将它们自动挂载到/media下
- /mnt 用户手动挂载点,不建议将设备直接挂载到/mnt目录之下,而应该先在其中创建子目录,然后分别将不同设备挂载到相应的子目录中。
自动挂载,mount挂载的设备在系统重启或关系时都会被自动卸载,这些开机后又需要手动挂载一遍。Linux系统可以通过修改/etc/fstab文件来完成存储设备的自动挂载。
一般linux下,修改系统文件的方式进行设置,需要重启才能生效。
可以通过 mount -a让系统自动挂载配置文件中的所有文件系统,而无需重启系统。
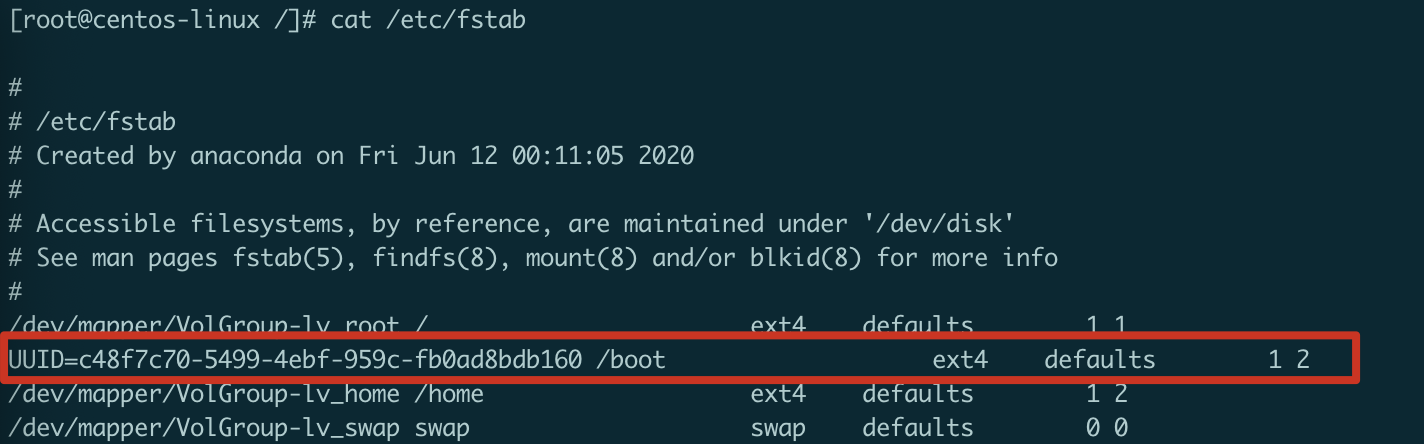
第一个字段:需要挂载的设备文件名。可以使用UUID
UUID(Universally Unique Identifier,全局唯一标识符)
通过设备文件名,可能每次插入的移动设备分配的名称会有变化,而UUID是不会变的。
blikid 设备文件查看设备文件的UUID第二个字段:挂载点
第三个字段:文件系统类型
第四个字段:挂载选项 ,一般采用“defaults”
第五个字段:存储设备是否需要dump备份,0表示忽略,1表示备份。
第六个字段:系统启动是是否检测这个存储设备,以及检测顺序。0表示不检测,1标识的设备检测完会检测2标识的设备
查看挂载的的情况
df -hT- df (disk free)
- h:人性化显示
- T:显示文件系统类型
结果中会有很多类型为tmpfs的文件系统,这些都是Linux中的临时文件系统,一般可以忽略。
df -hT | grep -v tmpfs过滤临时文件系统。如今ISO镜像使用的频率越来越高,因为光驱已经逐渐淘汰。在Linux系统中,可以将ISO镜像直接挂载使用。Linux系统将ISO镜像视为一种特殊的“回环”文件系统,因此在挂载时需要添加“-o loop“选项。
mount -o loop xxx.iso mnt/cdrom将ISO文件挂载到/mnt/cdrom目录
磁盘配额管理
略
磁盘阵列管理
传统机械硬盘性能提升缓慢,固态硬盘可靠性较低。
q: 如何提高硬盘性能,又增强数据存储安全性(备份)?
a: 多块硬盘组成RAID
RAID
RAID(Redundant Array of Independent Disks,独立冗余磁盘阵列),简称磁盘阵列。把多块独立的硬盘按照不同方式组合起来形成一个硬盘组。提供比单个硬盘更高的存储性能和数据备份能力。
从用户的角度看,组成的硬盘组就像一个硬盘,用户可以对它进行分区、格式化等,对磁盘阵列的操作与对单个硬盘基本一样。不同的是,磁盘阵列的读写速度要比单个硬盘高很多,而且可以提供自动数据备份功能。
RAID技术的两大特点:速度、安全。
有时我们希望提高硬盘的工作速度,有时希望提高数据的安全性,更多的时候希望二者兼得。因此,按照不同的用户需求,RAID提供了很多种不同的组合方式,这些组成磁盘阵列的不同方式就称为RAID级别。
常用的RAID级别:RAID0、RAID1、RAID10(RAID1 + RAID0) 和 RAID5
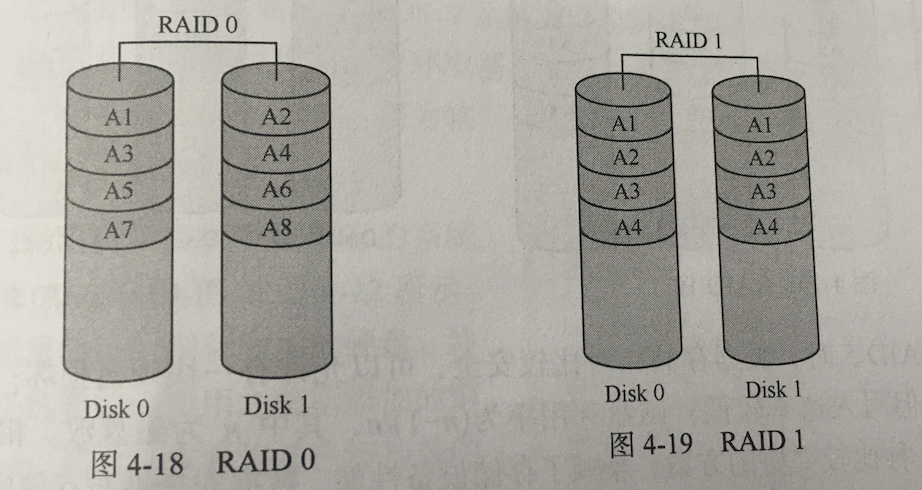
RAID0——提升硬盘读写速度
组建RAID0至少需要两块硬盘。
数据将分成数据块存储在不同的硬盘上。进行数据读写操作时,对于多块硬盘同时操作,从而大幅度提高硬盘工作性能。
所有RAID机级别中,RAID0存取速度最快,磁盘利用率最高。但是没有冗余,数据没有备份。
RAID1——数据备份
只需两块硬盘构成,将用户写入其中一块盘的数据原样地自动复制到另一块盘。读取数据时,先从源盘读取,如果读取失败,则转读备份盘。
RAID1提供了很高的数据安全保障,但写入速率低,使用一半的空间来存储备份数据,存储成本高。
RAID10——将RAID1和RAID0组合
四块硬盘实现,将四块硬盘分为两组,组成RAID1,以保证数据安全。然后将两个RAID1硬盘组成组RAID0,以提高读写速度。
读写性能出色,又具有非常高的安全性。但存储成本高,磁盘空间利用率只有50%。由于大部分情况下相比硬盘的价格,我们更加在乎数据的价值,因此RAID10在生产环境中被广泛应用。
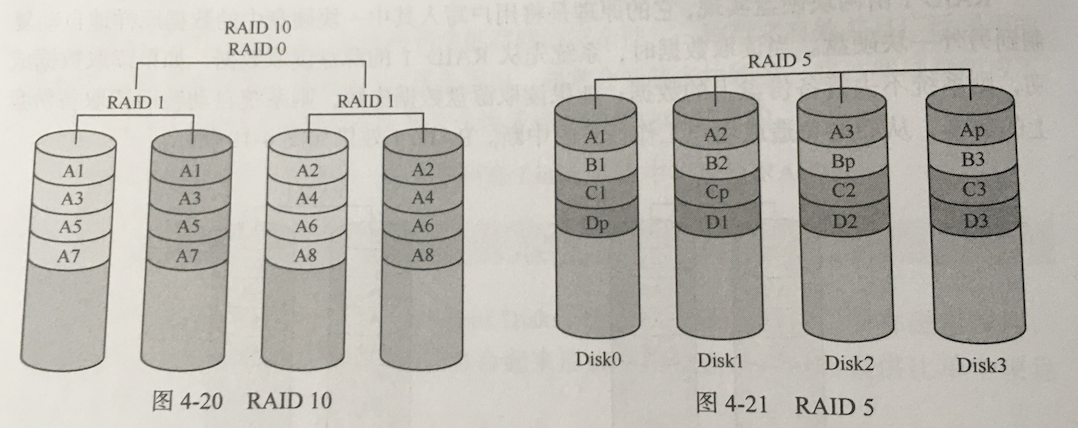
RAID5——将奇偶校验信息和数据较差起来进程存储
至少需要三块盘,将数据分布于不同的硬盘上,硬盘上交叉存储数据与校验信息。
这样任何一块盘损坏,都可以通过其他硬盘将其中数据恢复回来。
RAID5,存储数据相对较安全,数据读取速率较高,但写入速率较低;磁盘利用率为(n-1)/ n。
相比RAID10,是一种妥协的方案,兼顾存储性能、数据安全和储存成本,因而在生产环境中也被广泛采用。
RAID实现方式
软件RAID:占用一定系统资源,受操作系统稳定性影响。
硬件RAID:通过独立的RAID硬件显卡,目前大多数服务器配置了RAID卡或主板上集成了RAID控制芯片。不占用其他硬件资源,稳定性和速度都比软件RAID好。
逻辑卷管理(LVM)
逻辑卷管理是Linux系统中比较重要的一种磁盘管理机制,管理员利用LVM可以在磁盘不用重新分区的情况下动态调整文件系统的大小,并且利用LVM管理的文件系统可以跨越磁盘。
例如,系统中的sda1分区原先分配的容量,在使用一段时间后,发现容量不够用。
如果采用传统的磁盘管理机制,只能将sda硬盘重新分区,并给sda1分区分配更大的空间,但这样不可避免地会造成数据丢失,影响服务器的正常使用。
如果采用LVM机制,就可以在保证系统正常运行的前提下,随时为sda1分区增大空间,而且即使该分区所在的硬盘sda没有多余的空间可用,也可以随时为服务器添加新的硬盘,并将新的硬盘上的空间扩展到sda1分区中。当然,这里采用sda和sda1的方式进行描述,只是为了方便理解。当采用LVM机制后,传统意义上的硬盘会被组合成卷组(VG),然后从卷组中划分出逻辑卷(LV)来使用,逻辑卷就相当于传统意义上的磁盘分区。
LVM为我们提供了逻辑概念上的磁盘,使得文件系统不再关心底层物理磁盘的概念。LVM的出现实现了磁盘空间的动态调整和按需分配。
LVM是建立在物理磁盘和分区智商的一个逻辑层,通过它可以将若干个磁盘分区组合为一个整体的卷组,形成一个存储池。在卷组中可以任意创建逻辑卷,并进一步在逻辑卷上创建文件系统,最终在系统中挂载使用的就是逻辑卷。逻辑卷的使用方法和普通的磁盘分区完全一样。
重要概念:
物理卷(Physical Volume,PV )是构建LVM的基础,通常就是指磁盘或磁盘分区。实现LVM的第一步,将原先的磁盘或磁盘分区转换为LVM物理卷。
卷组(Volume Group,VG)是一个存储池,是LVM逻辑概念上的磁盘设备,可以将多个物理卷组合成一个卷组。
逻辑卷(Logical Volume,LV)是LVM逻辑概念上的磁盘分区,可以从指定卷组中提取指定的容量来创建逻辑卷,最后对逻辑卷进程格式化和挂载使用。
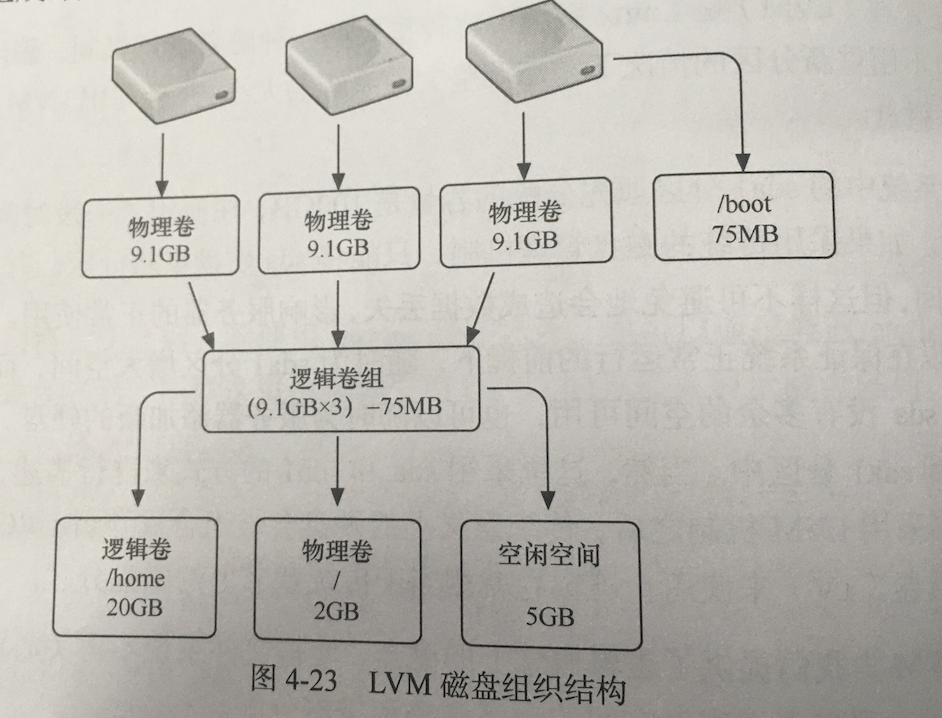
由于/boot目录用于存放系统引导文件,因此不能应用LVM机制。
逻辑卷的设备文件可以采用“/dev/卷组名/逻辑卷名“的方式。
CentOS 7安装过程中,自动分区采用LVM机制(除/boot)
pvs 查看系统中的已有物理卷
vgs 查看系统中的已有卷组
lvs 查看系统中的已有逻辑卷
1.创建物理卷pv
pvcreate /dev/sd{b,c} 将硬盘sdb、sdc转换为物理卷
pvdisplay /dev/sdb 查看置顶的pv:dev/sdb的信息
2.创建VG
vgcreate wgroup /dev/sd{b,c} 使用物理卷/dev/sdb,/dev/sdc创建名为wgroup的卷组
vgdisplay wgroup 查看指定卷组信息
3.创建逻辑卷LV
lvcreate -L 容量 -n 逻辑卷名 卷组名
lvcreate -L 39G -n ftp wgroup 从wgroup卷组中创建大小为39G的逻辑卷ftp。创建好的逻辑卷设备文件为/dev/wgroup/ftp
lvdisplay /dev/wgroup/ftp 查看逻辑卷信息
4.使用逻辑卷
mkfs -t xfs /dev/wgroup/ftp 格式化
mount /dev/wgroup/ftp /var/ftp
修改 /ect/fstab文件实现自动挂载
5.扩展逻辑卷空间
由于逻辑卷位于物理磁盘和分区之上的逻辑层,因此逻辑卷可以跨越物理磁盘。
当需要扩充逻辑卷的空间时,首先应保证它所在的卷组有可以分配的空余空间。我们可以按照以前的步骤,先添加一块盘,将其初始化物理卷之后,再加入卷组,这样就可以任意地调整逻辑卷的容量。
在调整容量之前先卸载设备和挂载点的关联 umount /var/ftp
将新的磁盘转换为物理卷 pvcreate /dev/sd{d,e}
将新的物理卷加入到卷组中 vgextend wgroup /dev/sd{d,e}
扩展逻辑卷的空间
vlextend -L +10G /dev/wgroup/ftp在原有基础上增加10G空间vlextend -L 10G /dev/wgroup/ftp将原有空间扩展到10G
以上完成了对逻辑卷物理边界的扩大,还需要扩大逻辑边界,也就是要更新文件系统的大小。这样,才能使逻辑卷的容量真正发生变化。
不同类型文件系统使用的命令不同:
- xfs:
xfs_growfs 扩展的逻辑卷 - EXT系列:
resize2fs 扩展的逻辑卷
6.删除LVM分区
卸载挂载点—删除逻辑卷—删除卷组—删除物理卷
umount /var/ftp
lvremove /dev/wgroup/ftp
vgremove wgroup
pvremove /dev/sd{b,c,d,e}
在卸载挂载点时注意删除 /etc/fstab相应的条目
用户和权限管理
useradd username 添加用户
passwd username 设置用户的登录密码
su username 切换当前的登录的用户
权限与归属
Linux系统中的每个文件或者目录都有两种属性:访问权限(读、写、执行)和文件归属(拥有文件的用户,拥有文件的组)
ls -l xxx 查看文件的权限和归属

第一列:文件类型+访问权限(所有者的权限+所属组的权限+其他用户的权限)
第二列:所有者
第三列:所属组
用户只要有有对目录的写入权限,就可以删除文件夹下的子目录和文件,而不用管这些文件或子目录是否属于该用户。
chmod修改文件的权限
chmod(change mode),只有root用户或者文件的所有者才有权限用chmod命令改变文件或目录的访问权限。
chmod两种修改文件权限的方式:
1.字符形式的chmod命令
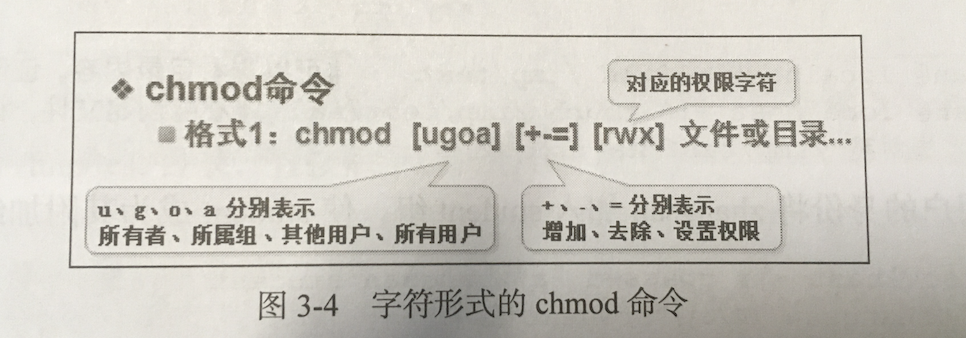
chmod o+w 文件
2.数字形式的chmod命令

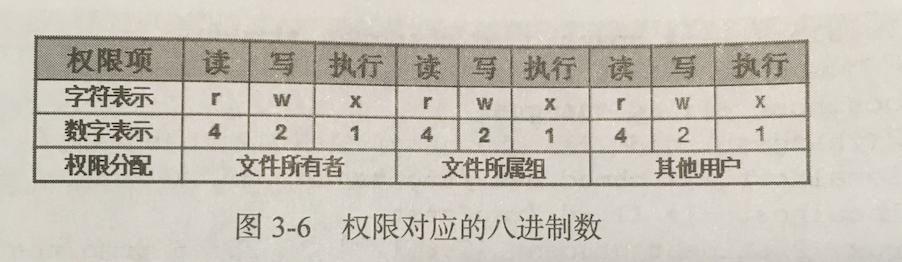
chmod 775 /tep/test
sudo
允许经过授权的个别普通用户以root权限执行一些授权使用的管理命令
sudo运行后,输入的是当前用户的密码,而不是root密码

archer用户使用sudo命令也无法创建用户,因为在Linux系统中只有被授权的用户才能执行sudo命令,而且使用sudo也只能执行那些被授权的命令。
因此要使用sudo命令必须先经过管理员的授权设置,修改配置文件/etc/sudoers
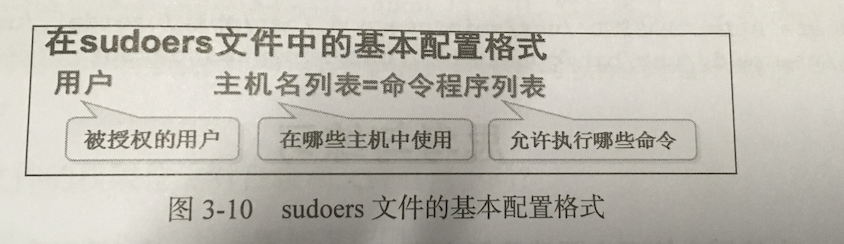
archer ALL=ALL 可以以sudo执行所有命令
archer ALL=/usr/sbin/useradd,/usr/sbin/userdel,/usr/bin/passwd
执行部分命令
archer ALL=NOPASSWD:/usr/sbin/useradd,/usr/sbin/userdel
执行后不需要输入密码
archer ALL=NOPASSWD:/usr/sbin/useradd,!/usr/bin/passwd root 通过!阻止用户执行指定的命令(阻止修改root的密码,😄)
Shell脚本
编译型编程语言:程序转换为二进制代码,计算机直接读取编译后的目标代码(object code),目标代码非常接近计算机底层,所有执行效率高。
解释型语言:又叫脚本语言,解释器一行为单位,将每行代码一次转换为二进制代码。每次执行程序都多了解释的过程,效率有所下降。
Shell更加类似于Windows系统中的批处理程序,是一些命令的集合。编写Shell脚本的目的是批量执行一系列系统命令,并通过选择、循环等程序结构加以控制。




